Это пятая статья из цикла «как надо делать ИТ». Напомню, что мы в «Депарамент ИТ» строим и обслуживаем корпоративные ИТ-инфраструктуры так, что наши клиенты работают, а не звонят в техподдержку.
Файловый сервер практически в любой компании – это самый неэффективный сервис с точки зрения соотношения размеров ценной информации к общим объемам занимаемого дискового пространства. Информация на файловых серверах зачастую сохраняется в десятках одинаковых экземплярах из-за плохо проработанной структуры хранения или же в виде сотен слабо отличающихся друг от друга разных версий одного и того же. К примеру, коммерческое предложение для каждого клиента представляет из себя отдельный файл на сервере, хотя все эти документы отличаются друг от друга зачастую только парой байт, поскольку сделаны по одному шаблону.
До выхода Windows Server 2012 R2 проблема неэффективного использования дискового пространства на файловых серверах не поддавалась решению (при использовании Windows Server в качестве файловых серверов). Файловые сервера в компаниях пухли как на дрожжах, требуя гигантских объемов хранения на серверах, системах хранения резервных копий, а также производительного сетевого оборудования для того, чтобы эти резервные копии вовремя делать. Но в Windows Server 2012 R2 наконец-то появился сервис дедупликации файлов на дисках. Сервис дедупликации сканирует все файлы на диске, разбивает их на части (чанки), находит схожие части с другими файлами и освобождает от дублей место на диске. Теперь, если в копии огромного документа поменять только пару фраз, место на диске под новый файл будет занято только этим изменением, а не повторением одного и того же.
Но давайте, для начала, от описания перейдем к демонстрации. На рисунке 1 можно увидеть результаты работы сервиса дедупликации на диске, содержащим перенаправленные профили пользователей. Несмотря на то, что у каждого пользователя в профиле хранится его личная информация, 27% этой информации дублируют друг друга:

Рис. 1. Результаты работы сервиса дедуплицаии на диске с перенаправленными профилями пользователей (FS-Users).
А вот файловый сервер в другой компании (Рис. 2). Тут на сервере хранятся не только перенаправленные профили пользователей, но и общий файловый ресурс. Как видим, среди перенаправленных профилей пользователей (диск FS-Users) объем дублированной информации выше, чем в случае общего файлового ресурса (диск FS-Storage), на котором информация структурирована:

Рис. 2. Результаты работы сервиса дедуплицаии на диске с перенаправленными профилями пользователей (FS-Users) и на диске с общим файловым ресурсом (FS-Storage).
Но самый потрясающий результат можно достигать на резервных копиях данных, когда на файловом ресурсе мы храним, к примеру, еженедельные резервные копии серверов. Поскольку данные в резервных копиях в массе своей повторяют друг друга, эффект от дедупликации превышает 50% (Рис. 3):
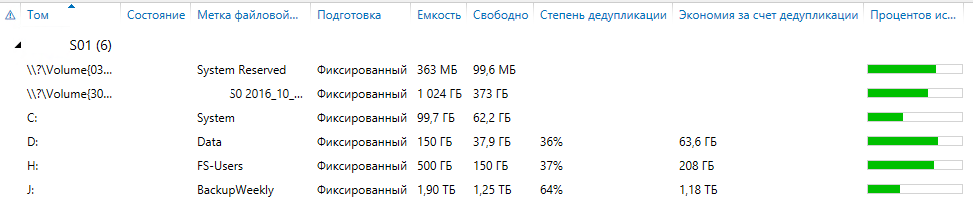
Рис. 3. Результаты работы сервиса дедупликации на диске с перенаправленными профилями пользователей (FS-Users), на диске с общим файловым ресурсом (FS-Storage) и на диске с еженедельными резервными копиями серверов (BackupWeekly).
Как вы видите, функция дедупликации файлов дает очень приятные результаты. Но у службы дедупликации в Windows Server есть и серьезный недостаток – она сильно замедляет файловый сервер во время своей работы. В других операционных системах функция дедупликации хранит в оперативной памяти информацию о сегментах, которые могут дублироваться, и это позволяет делать дедупликацию «на лету» – на диск пишутся только новые данные. В Windows Server дедупликации «на лету» нет: файл сначала записывается на диск, а уже потом, в фоновом режиме или по расписанию, делается его сверка с другими файлами и это сильно замедляет работу файлового сервера. По этой причине дедупликацию в Windows Server можно применять только на ненагруженных системах, и имеет смысл делать ее во внерабочее время и только для тех файлов, которые давно не изменялись.
На этом пока все, низкой энтропии вам на файловых серверах и бесперебойной ИТ-инфраструктуры.
